mPLUG-Owl3是阿里巴巴推出的通用多模态AI模型,专为理解和处理多图及长视频设计。在保持准确性的同时,显著提升了推理效率,能在4秒内分析完2小时电影。模型采用创新的Hyper Attention模块,优化视觉与语言信息的融合,支持多图场景和长视频理解。mPLUG-Owl3在多个基准测试中达到行业领先水平,其论文、代码和资源已开源,供研究和应用。
mPLUG-Owl3的主要功能
- 多图和长视频理解:能快速处理和理解多张图片和长时间视频内容。
- 高推理效率:在极短时间内完成对大量视觉信息的分析,如4秒内处理2小时电影。
- 保持准确性:在提升效率的同时,不牺牲对内容理解的准确性。
- 多模态信息融合:通过Hyper Attention模块,有效整合视觉和语言信息。
- 跨模态对齐:模型训练包括跨模态对齐,提升对图文信息的理解和交互能力。
mPLUG-Owl3的技术原理
- 多模态融合:模型通过将视觉信息(图片)和语言信息(文本)融合,以理解多图和视频内容。通过自注意力(self-attention)和跨模态注意力(cross-attention)机制实现的。
- Hyper Attention模块:一个创新的模块,用于高效整合视觉和语言特征。通过共享LayerNorm、模态专属的Key-Value映射和自适应门控设计,优化了信息的并行处理和融合。
- 视觉编码器:使用如SigLIP-400M这样的视觉编码器来提取图像特征,并通过线性层映射到与语言模型相同的维度,以便进行有效的特征融合。
- 语言模型:例如Qwen2,用于处理和理解文本信息,并通过融合视觉特征来增强语言表示。
- 位置编码:引入多模态交错的旋转位置编码(MI-Rope),保留图文的位置信息,确保模型能理解图像和文本在序列中的相对位置。
mPLUG-Owl3的项目地址
- GitHub仓库:https://github.com/X-PLUG/mPLUG-Owl/
- HuggingFace链接:https://huggingface.co/spaces/mPLUG/mPLUG-Owl3
- arXiv技术论文:https://arxiv.org/pdf/2408.04840
如何使用mPLUG-Owl3
- 环境准备:确保计算环境中安装了必要的软件和库,例如Python、PyTorch或其他深度学习框架。
- 获取模型:从GitHub、Hugging Face获取mPLUG-Owl3模型的预训练权重和配置文件。
- 安装依赖:根据模型的文档说明,安装所需的依赖库,可能包括特定的深度学习库、数据处理库等。
- 数据准备:准备想要模型处理的数据,例如图片、视频或图文对。确保数据格式符合模型输入的要求。
- 模型加载:使用适当的深度学习框架加载预训练的mPLUG-Owl3模型。
- 数据处理:将数据进行预处理,以适配模型的输入格式。包括图像大小调整、归一化、编码等步骤。
- 模型推理:使用模型对数据进行推理。对于多图或视频内容,模型将输出对内容的理解和分析结果。
mPLUG-Owl3的应用场景
- 多模态检索增强:mPLUG-Owl3 能准确理解传入的多模态知识,并用于解答问题,甚至能够指出其做出判断的具体依据。
- 多图推理:能理解不同材料中的内容关系,进行有效推理,例如判断不同图片中动物是否能在特定环境中存活。
- 长视频理解:mPLUG-Owl3 能在极短时间内处理并理解长时间视频内容,对视频的开头、中间和结尾等细节性片段提问时,都能迅速给出回答。
- 多图长序列理解:多图长序列输入的场景,如多模态多轮对话和长视频理解等,展现了高效的理解和推理能力。
- 超长多图序列评估:在面对超长图像序列和干扰图像时,mPLUG-Owl3 显示出了高鲁棒性,即使输入数百张图像仍保持高性能。
本站资源来源于网络,仅限用于学习和研究目的,请勿用于其他用途。如有侵权请发送邮件至vizenaujmaslak9@hotmail.com删除。:FGJ博客 » mPLUG-Owl3 – 阿里巴巴推出的通用多模态AI模型
 Rank Math Pro插件相比Rank Math普通版多了哪些功能
Rank Math Pro插件相比Rank Math普通版多了哪些功能 独立站如何利用AI自动生成文章
独立站如何利用AI自动生成文章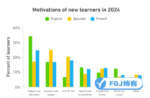 2024年全球语言趋势学习报告 – 意大利语竟然排到了第六
2024年全球语言趋势学习报告 – 意大利语竟然排到了第六 让生活更多彩的MagicMirror – 开源AI换脸软件
让生活更多彩的MagicMirror – 开源AI换脸软件 InstructMove – 指令式图像编辑AI模型
InstructMove – 指令式图像编辑AI模型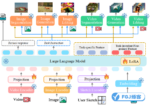 VITRON – 图像视觉大型语言模型
VITRON – 图像视觉大型语言模型 Twee – 为英语教师量身打造的AI辅助备课工具
Twee – 为英语教师量身打造的AI辅助备课工具 aftershoot:摄影师的AI助手
aftershoot:摄影师的AI助手