说到VITRON,这是Skywork AI和新加坡两所顶尖高校国立大学和南洋理工大学共同推出的视觉语言模型。用大白话讲,这个模型就好比一个全能工具,可以处理各种静态图像和动态视频的活儿。你可以让它理解图片,生成新图像,甚至还可以剪辑视频,无所不能。
VITRON项目:https://vitron-llm.github.io/
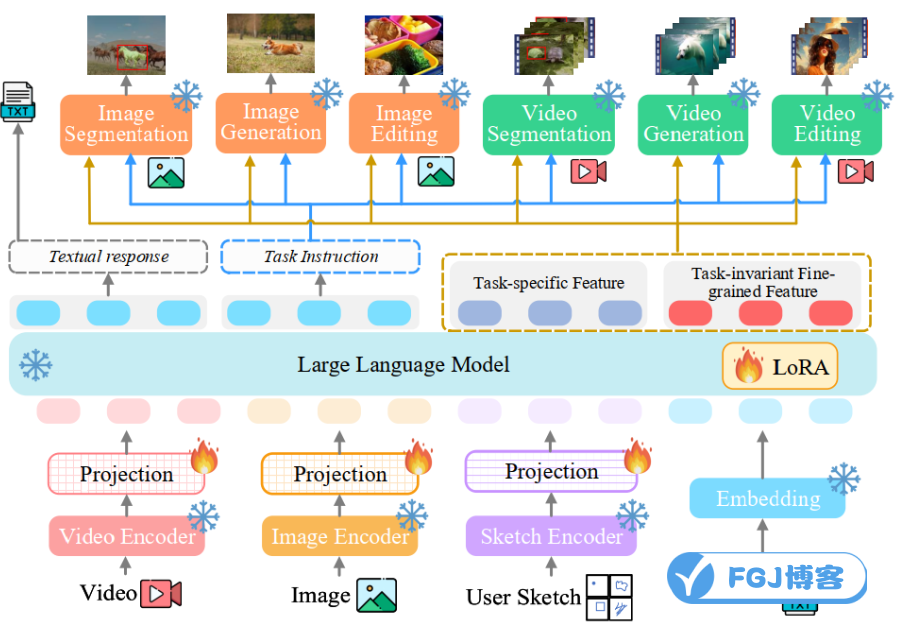
先聊聊它能干啥。VITRON可以搞定图像和视频的问答,比如“这张图片里有啥?”或者“视频里的人在干嘛?”。要是有模棱两可的内容,它也能搞定。生成图片和视频也是小菜一碟,只要输入文字,它就能帮你“变出”需要的图像。不仅如此,VITRON还能做分割,不管是要找到某个东西或是整个场景,它都能行。另外,它在照片和视频编辑方面也很在行,想加个东西进去、换掉或是改个色,它都能做到。
技术方面,VITRON用一种叫做“编码器-LLM-解码器”的架构,也就是先理解输入的图像和视频,然后通过语言模型理解,最后解码,完成具体的任务。前端用CLIP ViT-L/14@336px这样的高科技玩意儿来处理每帧视频,还可以用来分析用户的手动输入。同心协力的核心语言模型Vicuna(7B, 版本1.5)则承担语义理解和推理的重任,这可以说是这个系统的大脑。而在处理具体任务的时候,GLIGEN、SEEM这样的专家会轮流上阵,他们各有专长,比如说图像生成、视频分割啥的。
VITRON最牛的地方在于它的“混合方法”,可以确保指令传达到位,就像是高手传授秘籍那样精准。
这些技能到底派啥用场?想象一下吧:在照片编辑方面,它可以帮你美化图片,去除不想要的背景或是物体;在视频创作上,它可以依剧本自动生成视频内容,简直就是导演的最佳助攻。还有在线教育啊、电商平台、新闻媒体等许多地方都用得上。比如,教育平台上的教学视频自动生成,电商平台让商品更吸睛的视频展示,新闻报道中快速生成的图文资料,都是它能做的。
就像你会告诉朋友你的新发型是在哪儿弄的一样,这项技术的项目也有自己的专属网页和GitHub,可以去了解个更清楚。怎么样,听完有木有觉得这个工具相当全能呢?
本站资源来源于网络,仅限用于学习和研究目的,请勿用于其他用途。如有侵权请发送邮件至vizenaujmaslak9@hotmail.com删除。:FGJ博客 » VITRON – 图像视觉大型语言模型
 Rank Math Pro插件相比Rank Math普通版多了哪些功能
Rank Math Pro插件相比Rank Math普通版多了哪些功能 独立站如何利用AI自动生成文章
独立站如何利用AI自动生成文章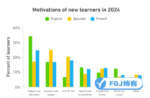 2024年全球语言趋势学习报告 – 意大利语竟然排到了第六
2024年全球语言趋势学习报告 – 意大利语竟然排到了第六 让生活更多彩的MagicMirror – 开源AI换脸软件
让生活更多彩的MagicMirror – 开源AI换脸软件 InstructMove – 指令式图像编辑AI模型
InstructMove – 指令式图像编辑AI模型 Twee – 为英语教师量身打造的AI辅助备课工具
Twee – 为英语教师量身打造的AI辅助备课工具 aftershoot:摄影师的AI助手
aftershoot:摄影师的AI助手 WPML插件多语言网站翻译设置教程
WPML插件多语言网站翻译设置教程